Posts
-
Leveling Up CIDER's ClojureScript Support
Continuing the series on the notable changes in CIDER 2.0, let’s talk about ClojureScript - forever the trickier sibling in the CIDER family.
I’ll start with a confession I’ve made before: I rarely use ClojureScript myself, which is a big part of why its support in CIDER has historically lagged behind Clojure’s. Every “State of CIDER” survey reminds me of this, usually in the comments section, occasionally in all caps. So in the 2.0 cycle I decided to stop feeling vaguely guilty about it and actually do something - across every layer of the stack: CIDER itself,
cider-nrepl, and Piggieback.First, a strategic decision
The most important ClojureScript change in CIDER 2.0 isn’t a feature - it’s a decision about what not to build. Some of CIDER’s most powerful tools (the debugger, enlighten, tracing, profiling) are deeply tied to JVM runtime introspection, and porting them to ClojureScript would be a massive effort with a poor cost/benefit ratio. Rather than keeping them in eternal “maybe someday” limbo, we’ve explicitly scoped them as Clojure-only and focused the actual work on the things cljs users hit every day: evaluation, testing, error reporting, and clear behavior everywhere else.
That last part matters more than it sounds. Historically, invoking a JVM-only command in a ClojureScript REPL would fail in some confusing way - a cryptic error, a JVM-flavored result, or silence. Now the ops themselves report a
clojure-onlystatus, and CIDER tells you plainly that the command isn’t supported for ClojureScript. Knowing what a tool won’t do is half of trusting it.What actually got better
- The regular test commands (
cider-test-run-ns-testsand friends) now work in ClojureScript REPLs, asynchronouscljs.test/asynctests included. Previously CIDER just refused, and you were stuck evaluating(run-tests)by hand like an animal. - Expanding your own macros (e.g.
ones brought in via
:refer-macros) used to silently echo the form back unexpanded - a bug filed all the way back in 2017. The compiler environment is now threaded to the analyzer properly, and it just works. cider-nreplnow resolves the ClojureScript compiler environment through a provider chain, with a dedicated shadow-cljs provider - so the static-analysis ops keep working in a shadow REPL that never loads Piggieback.- The new
cider-tapviewer works with ClojureScript too: a runtime helper buffers tapped values and the JVM side streams them to Emacs. (Tapped cljs values aren’t inspectable - they live in the JS runtime - but you see them as they happen.) - ClojureScript stack frames now render their
ns/fnproperly instead of degrading tonil/nil, and unqualified core vars resolve againstcljs.corerather than falling back toclojure.core(which quietly broke things like indentation metadata). - A recent ClojureScript on the classpath (whose
Closure compiler wants JDK 21+) no longer crashes
cider-nreplat startup on an older JDK - you get a Clojure-only session instead of no session. - Piggieback itself got a round of bug fixes in the 0.6.x/0.7.0 releases - it’s easy to forget it exists (which is rather the point of it), but it powers most cljs REPLs CIDER talks to.
The documentation kept pace too: the new full-stack Clojure + ClojureScript guide covers the two-REPLs-one-project setup that trips up nearly everyone, and the ClojureScript docs got a general refresh.
An unexpected assist
Fun aside: this is the area where AI coding agents helped me the most during the 2.0 cycle. My ClojureScript experience is limited, but between the excellent bug reports from the community and the ability to quickly prototype and test fixes against real shadow-cljs and figwheel setups, problems that had been “someone who knows cljs should look at this someday” for years finally got fixed. Make of that what you will.
What’s next
I keep pondering some form of “native” shadow-cljs support, given that shadow-cljs is what most ClojureScript users actually run these days. That’s still very much in the hammock phase, so don’t hold me to it - but the direction is clear: fewer moving parts, clearer errors, and honesty about what’s supported.
If you’re a ClojureScript user, I’d genuinely love to hear how 2.0 feels in your daily work - the feedback loop is what keeps this improving. Keep hacking!
Articles in the Series
- The regular test commands (
-
Sharpening CIDER's Debugging Tools
The series on the notable changes in CIDER 2.0 rolls on. This time: the “what is my code actually doing?” toolbox - the debugger, tracing, enlighten, and the new tap viewer. This was the part of the release I enjoyed working on the most, and the part that needed the most love.
The debugger, dusted off
CIDER’s interactive debugger is one of its most impressive features and, paradoxically, one of its least reliable ones. Instrumenting arbitrary Clojure code is hard - the debugger rewrites your forms to capture locals at every step, and the corner cases are endless. Over the 2.0 cycle (and the 0.62.x releases of
cider-nrepl) a whole family of long-standing instrumentation bugs got fixed:- Record literals embedded in code survive instrumentation instead of being quietly downgraded to plain maps - which used to break protocol dispatch in anything that compiled routes or components into records (compojure users know the pain).
defrecord/deftypeinline methods no longer blow up with the infamousUnable to resolve symbol: STATE__error - the instrumenter now sensibly skips the method bodies, which compile to real JVM methods that can’t capture debugger state.#dbgon a bare collection literal triggered the same error; fixed too. And heavily destructured argument lists used to crash instrumentation in their own special way - not anymore.- A form too large to instrument (yes, that’s a JVM limitation -
Method code too large!) now degrades gracefully: CIDER retries without local capture and tells you what happened, instead of surfacing a raw compiler error. - Quitting a debug session uses nREPL’s interrupt machinery instead of the
deprecated
Thread.stop, so it keeps working on modern JDKs whereThread.stopis simply gone.
The UX got attention too. Quitting the debugger with
qfinally restores point to where you started the session - a request filed in 2016 - instead of stranding you at the last breakpoint. The force-step-out key works again. And all the debugger’s single-key commands are now proper named commands with a transient menu (?) listing them, so you’re never stuck trying to remember whether locals waslorL.Tracing grew a home
clojure.tools.trace-style tracing has been in CIDER forever, but the output was always interleaved into the REPL, where it fought with your actual work. CIDER 2.0 gives traces a dedicated, live-streaming*cider-trace*buffer: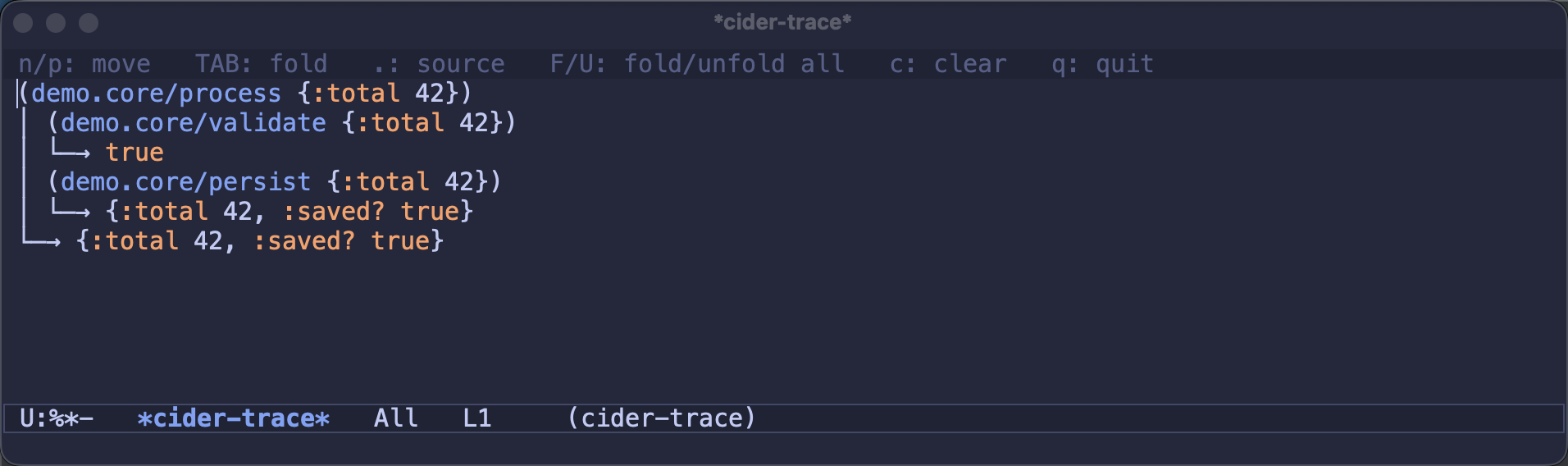
Calls fold and unfold (
TAB, orF/Ufor everything at once),n/pmove between calls, and.jumps to a function’s definition.cider-list-tracedanswers the eternal “wait, what did I even trace?”, andcider-untrace-allcleans the slate.Enlighten, back from the dead
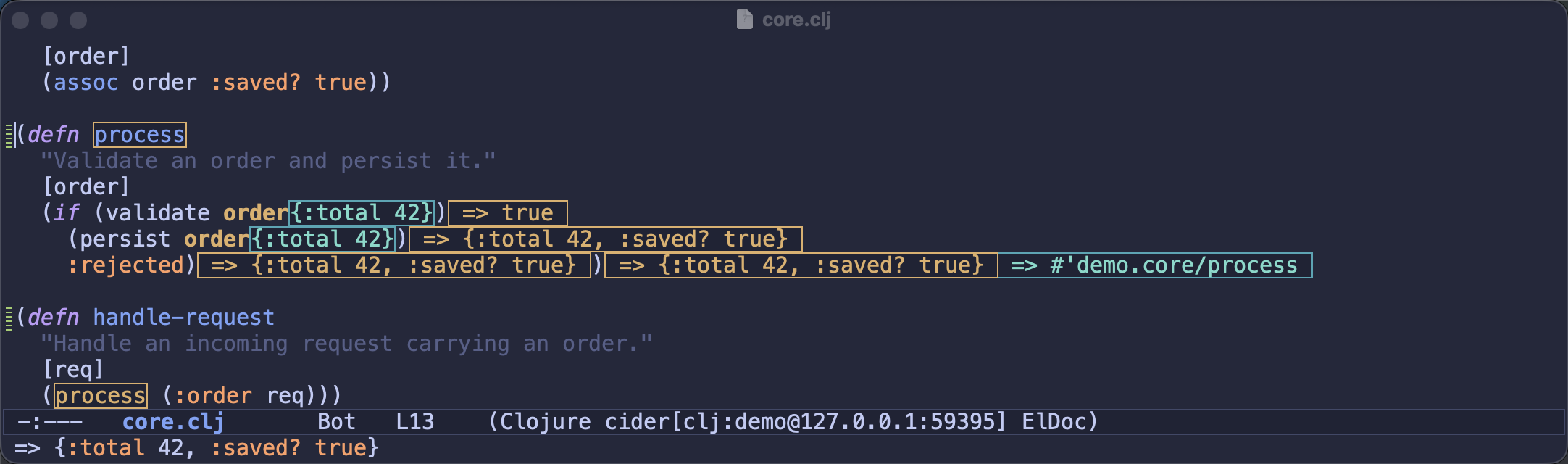
Enlighten - the mode that displays the values of locals inline as your code runs - has been in “experimental” limbo since 2016. It finally got a proper overhaul: a real test suite, fixes for the same record/deftype instrumentation bugs as the debugger (they share machinery), and - importantly - manners. You can now enlighten a single form with
cider-enlighten-defun-at-pointinstead of flipping a global mode, andcider-enlighten-stopturns everything off at once, rather than making you re-evaluate every function in penance.Every local and every intermediate result, right there in the buffer:
Tap into your programs
New in 2.0:
cider-tap, a buffer that streams every value sent totap>and lets you crack any of them open in the inspector withRET.tap>has quietly become the Clojure community’s favorite debugging primitive, and now you don’t need an external tool like Portal or Reveal for the basic workflow - though those remain great if you want more. (ClojureScript taps stream too; they’re just not inspectable, since the values live in the JS runtime.)It’s
printlndebugging, minus the println guilt.The connective tissue
A few related quality-of-life items round out the picture: stack frames for top-level anonymous functions jump to their actual source instead of
clojure.core/fn(a bug from 2020), ClojureScript frames render theirns/fnproperly, and the macroexpansion tooling - a debugging tool in its own right - got a full makeover that deserves (and will get) its own article.None of these tools is new. That’s rather the point: the 2.0 debugging story is mostly the existing tools becoming trustworthy. A debugger you don’t trust is worse than no debugger at all.
The debugging docs cover everything in detail. Keep hacking!
Articles in the Series
-
Projectile 3.3
Projectile 3.3 is out! That’s the fourth release this month, which probably tells you something about how much fun I’ve been having with Projectile lately.
This one is mostly about a single theme - Projectile knowing more about your project without you having to tell it anything.
Read More -
Closing the Find-Usages Gap in CIDER
Next up in the series on the notable changes in CIDER 2.0: cross-references. Or, as most people call the feature, “find usages” - for years the most commonly cited reason to run clojure-lsp alongside (or instead of) CIDER. Let’s talk about why that gap existed and how we finally closed it.
Why runtime xref wasn’t enough
CIDER has had runtime cross-referencing for a while: the
cider/fn-refsop walks the loaded vars in your REPL and reports which functions reference the one at point. It’s a genuinely cool trick - the REPL literally knows your program - but as a “find usages” answer it has three structural problems:- It only sees loaded code. Namespaces you haven’t required yet - often most of the codebase - are invisible.
- It reports functions, not occurrences. Each hit points at the caller’s definition, not the exact call site, and a function that calls yours three times shows up once.
- It’s JVM-only, so ClojureScript users got nothing.
clojure-lsp, by contrast, builds a static index of your whole project with clj-kondo’s analyzer and answers instantly, loaded or not. For occurrence-oriented questions (“show me every place this is used, so I can change all of them”), static analysis is simply the right tool. No amount of runtime cleverness fixes “the code isn’t loaded”.
The fix: search the source
So CIDER 2.0 does the obvious thing we should have done years ago:
xref-find-references(M-?) now finds references by searching the project’s source files on disk. Unloaded code,cljsfiles, commented-out drafts - if the name occurs in the project, you’ll see the exact occurrence, in the standard xref UI you already use for everything else in Emacs. To borrow the franchise that has been handing programmers debugging metaphors for over two decades now: the runtime is the Matrix, a tidy compiled illusion of your program, and to see every place a thing is really used you sometimes have to unplug and look at the source itself.1Here’s the difference in one picture - the same query on
orchard.misc/require-and-resolve, first in runtime mode, then in source mode: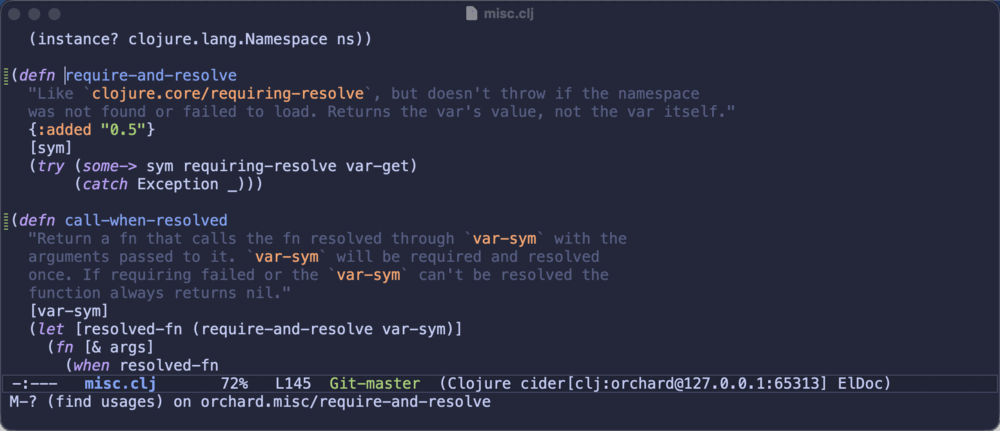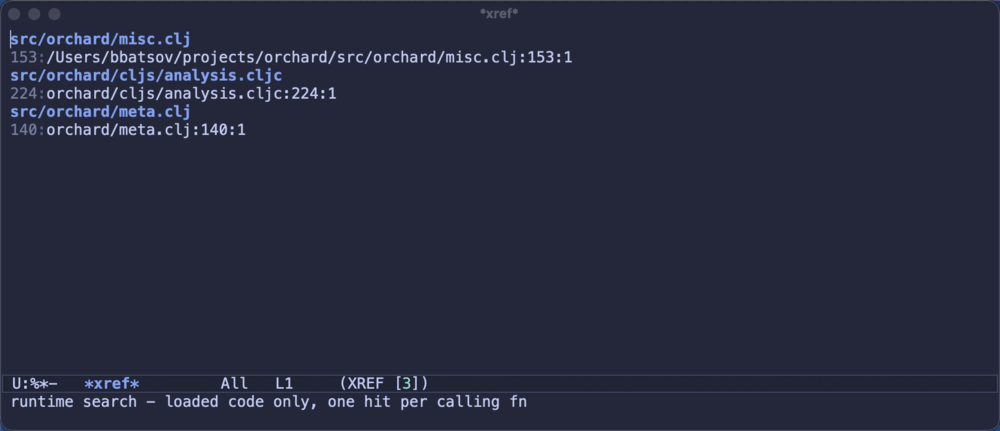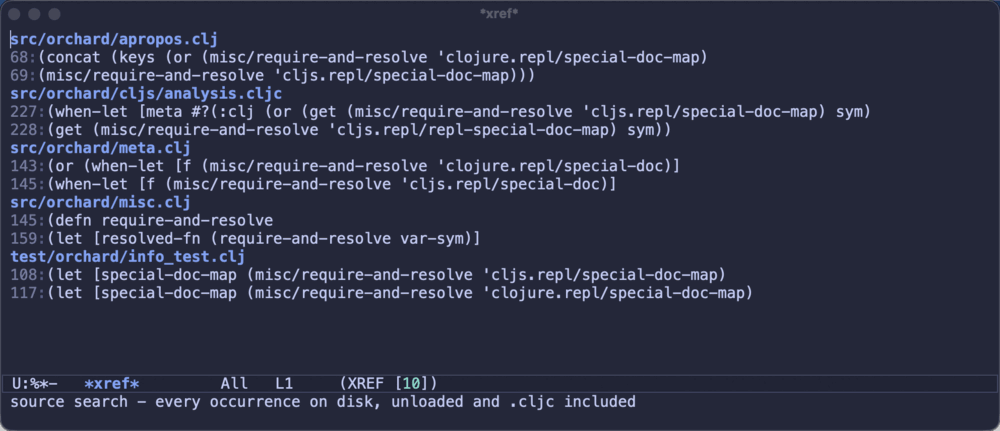
The runtime knows about three callers - and points you at each caller’s definition. The source scan turns up all ten actual occurrences, across five files, including the ones written as
misc/require-and-resolvein namespaces the REPL never loaded. That’s the gap, in one screenshot.Now, “search the source” makes it sound like a
grep, and I want to be clear that it isn’t a dumb one. Say you’re chasingorchard.misc/require-and-resolve. The search runs in three stages:- First CIDER asks the REPL to resolve the symbol at point to its fully
qualified name,
orchard.misc/require-and-resolve. The REPL is right there on the other end of the wire, so why guess when you can ask? - A fast first pass (
ripgrep, via Emacs’ ownxref-matches-in-files) finds every file that so much as mentionsrequire-and-resolve, purely to narrow the field. - Then the Clojure-aware part. For each of those files, CIDER reads its
(ns ...)form to learn how that file pulls inorchard.misc- aliased as[orchard.misc :as misc], brought in with:refer [require-and-resolve], or is thisorchard.miscitself? - and builds a regexp that matches only the forms that file could legitimately use: the qualifiedorchard.misc/require-and-resolve, the aliasedmisc/require-and-resolve, or a barerequire-and-resolvewhere the namespace declaration makes that valid. The requires inside thensform are excluded, so the import line doesn’t show up as a “usage”.2
Is any of this as smart as clj-kondo’s full analysis? No - it’s ultimately a syntactic search, so an identically named var in another namespace can still sneak through as a false positive. But because it’s ns-aware rather than a blind text match, a bare
require-and-resolvein some file that never requiresorchard.misc(and has arequire-and-resolveof its own) won’t be mistaken for yours. For the daily “where is this used?” question it turns out to be remarkably close to the real thing in practice, it requires zero extra infrastructure, and it composes with what only CIDER has: the running REPL.That composition is configurable via
cider-xref-references-mode:source(the default) - occurrences from the project’s files.runtime- the historical loaded-vars behavior.both- source occurrences first, plus the runtime hits the scan can’t see. And there are such hits: references generated by macro expansion leave no textual trace in your source, but the runtime knows about them. Static analysis can’t ever tell you those; your REPL can.
(There’s also
cider-xref-fn-refs-in-source,C-c C-? s, when you want the source search explicitly, and outside a project the source mode gracefully falls back to the runtime search.)Beyond find usages: the who-* family
While closing the gap, we went further and built out a whole family of SLIME-inspired cross-referencing commands under
C-c C-w, most of them rendered as expandable trees:-
cider-who-calls/cider-who-is-called- the call graph, upward and downward. Expand a caller to see its callers; spelunk as deep as you like: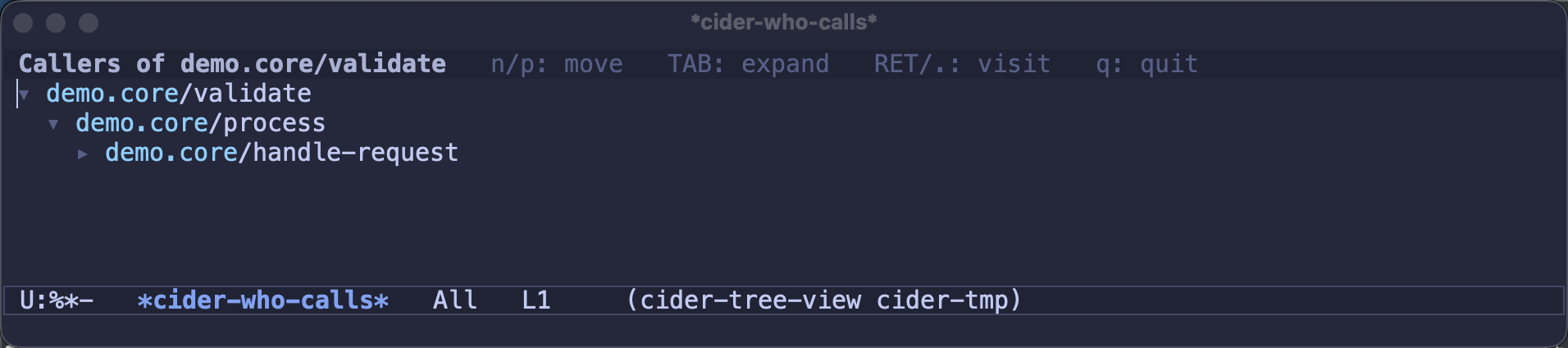
cider-who-implements- a protocol’s implementing types (inlinedefrecord/deftypeimplementations included) or a multimethod’s dispatch values, each jumping to the implementation’s source. Multimethods are a nice case study in hybrid thinking: the method functions carry no source metadata at runtime, so CIDER locates thedefmethodforms by - you guessed it - searching the source.cider-type-protocols/cider-protocols-with-method- the reverse lookups: what does this type implement, and which protocols declare this method?cider-who-macroexpands- a macro’s use sites, found via source search, because macro invocations are expanded away at compile time and the runtime literally cannot see them.
Much of this is powered by new ops in
cider-nrepl(and Orchard underneath), and much of the inspiration came straight from SLIME and swank-clojure, which offeredwho-callsback when Clojure itself was barely out of the crib. And here’s the part I love: the whole “go read the source instead of trusting the runtime” instinct was already there in swank-clojure’s implementation. Itswho-callswould find candidate callers among the loaded vars, sure, but then it went and read the actual source form of each one off disk and walked the parsed code looking for your symbol, rather than believing whatever the compiled runtime claimed. It was still anchored to loaded code - it never scanned the whole project the way CIDER 2.0 does - but the core idea, that the source on disk is the ground truth and the runtime is just a convenient approximation, predates this release by about fifteen years. Good ideas don’t expire. Sometimes nothing beats revisiting the classics.3So do you still need clojure-lsp?
If you were running clojure-lsp primarily for find-usages - the most common answer I heard when I asked - then CIDER now covers you out of the box. If you use it for project-wide renames, unused-var linting, or editing without a REPL, carry on; those are real strengths of static analysis and CIDER doesn’t try to replicate them. The two continue to work fine side by side, and the new async eldoc even yields politely so LSP-provided docs can compose with CIDER’s.
My goal was never to “beat” clojure-lsp - it was to make a freshly installed CIDER answer the questions every Clojure programmer asks a dozen times a day, with no extra moving parts, and with the one advantage nobody else has: a live runtime on the other end of the wire.
The full story is in the navigation docs. Keep hacking!
Articles in the Series
- CIDER 2.0: Sky is the Limit
- Simplifying Session Management in CIDER
- Stepping Through Macros in CIDER
- Making CIDER More Discoverable
- Modernizing CIDER's Completion
- Closing the Find-Usages Gap in CIDER
- Sharpening CIDER's Debugging Tools
- Leveling Up CIDER's ClojureScript Support
-
As Morpheus puts it: “Unfortunately, no one can be told what the Matrix is. You have to see it for yourself.” Same with find-usages, really - I can tell you a var is used in seven places, but until you’ve seen the actual call sites you don’t really know what changing it will break. ↩
-
Full disclosure: matching the aliased and namespace-qualified forms correctly only landed after 2.0 - the 2.0.x releases had a bug where the source scan quietly skipped files that referenced a var through its alias, which is of course the common case. The fix will ship in CIDER 2.1, which doesn’t have a release date yet. I’m hoping to get back into a rhythm of cutting a new CIDER release every month or two, so it shouldn’t be a long wait. ↩
-
“The path of the One ends at the Source.” The Architect was talking about Zion, but he might as well have been describing every debugging session that ends with you finally opening the file and reading the code instead of theorizing about it. ↩
-
Modernizing CIDER's Completion
CIDER’s code completion has quietly gotten quite good over the years, and I don’t think it gets enough credit. It’s all built on Emacs’s standard
completion-at-point, so it works with whatever completion UI you prefer - the built-in one, Corfu, company - without any special setup. Under the hood compliment does the heavy lifting for Clojure (and clj-suitable for ClojureScript), which means smart, backend-driven matching:maicompletes tomap-indexed,cjitoclojure.java.io, and an unimportedBiFuntojava.util.function.BiFunction. The candidates come back ranked by the backend and are context-aware - it knows when you’re inside a->or completing adeftypefield.Lately I’ve been giving the Emacs side of things some attention, to bring it in line with the modern completion stack so many of us now use - Vertico, Corfu, Consult, Marginalia and friends. Two changes are worth calling out.
The first is about the symbol prompts. A number of CIDER commands ask you for a Clojure symbol when there’s nothing at point -
cider-doc,cider-find-varand the like. Historically those prompts used the older completion machinery, so yourcompleting-readUI didn’t kick in and you were left withTABand a*Completions*buffer. There’s nowcider-use-completing-read-for-symbol(off by default for now); turn it on and those prompts go throughcompleting-readover a collection that queries the running REPL lazily as you type. Vertico, Ivy, Helm - whatever you drivecompleting-readwith - just works, and the candidates carry their type and namespace.The second is smaller, but I like it a lot: annotations now line up in a proper column instead of trailing raggedly after each candidate.
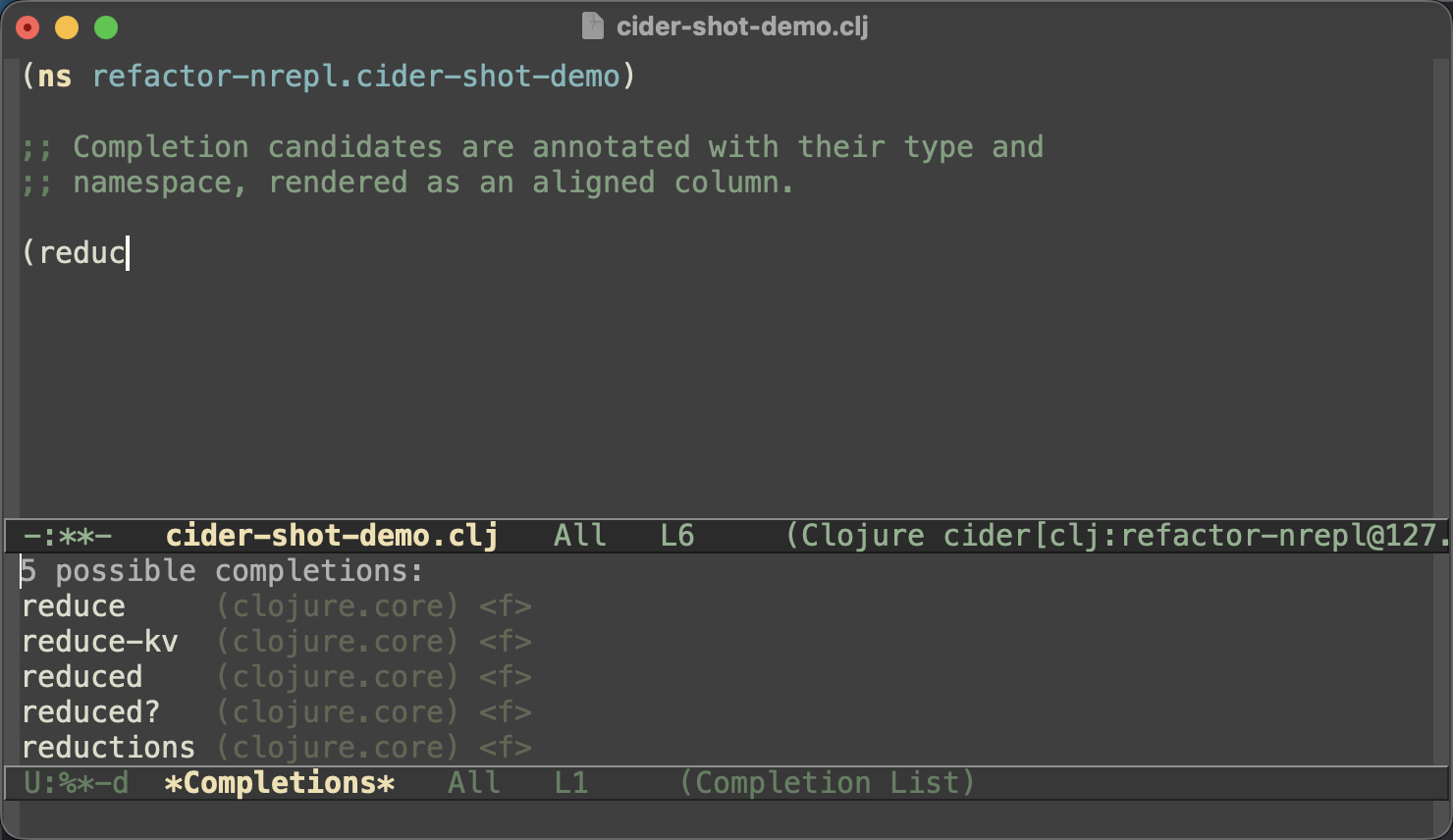
This comes from an
affixation-function, the richer successor to the oldannotation-function, so every frontend that understands it - the built-in*Completions*, Corfu, Vertico - renders the aligned version. company keeps showing its own trailing annotations, same as before.Both changes are in the latest CIDER MELPA build and will ship in the next stable release. As always, I’d love to hear how they work out for you.
That’s all I have for you today. Keep hacking!
P.S. If you use Embark, I wrote up a fun way to act on Clojure symbols with it - documentation, jump-to-definition, inspect and so on - over on Emacs Redux.
Articles in the Series
Subscribe via RSS | View Older Posts