Posts
-
nREPL 1.4
nREPL 1.4.0 is out! This month we celebrate 15 years since nREPL’s development started, so you can consider this release part of the upcoming birthday celebrations.
So, what’s new?
Probably the highlight is the ability to pre-configure default values for dynamic variables in all nREPL servers that are launched locally (either per project or system-wide). The most useful application for this would be to enable
*warn-on-reflection*in all REPLs. To achieve this, create~/.nrepl/nrepl.ednwith this content:{:dynamic-vars {clojure.core/*warn-on-reflection* true}}Now, any nREPL server started from any IDE will have
*warn-on-reflection*enabled.$ clojure -Sdeps "{:deps {nrepl/nrepl {:mvn/version \"1.4.0\"}}}" -m nrepl.cmdline -i user=> #(.a %) Reflection warning, NO_SOURCE_PATH:1:2 - reference to field a can't be resolved.Note: nREPL doesn’t support directly
XDG_CONFIG_HOMEyet, but you can easily override the default global config directory (~/.nrepl) withNREPL_CONFIG_DIR.Another new feature is the ability to specify
:client-nameand:client-versionwhen creating a new nREPL session with thecloneoperator. This allows collecting information about the clients used, which some organizations might find useful. (I know Nubank are making use of this already)One notable change in nREPL 1.4 is the removal of support for Clojure 1.7. Clojure 1.7 was released way back in 2015 and I doubt anyone is using it these days, but we try to be extra conservative with the supported Clojure versions and this is only the second time nREPL’s runtime requirements were bumped in the 7 and a half years I’ve been the maintainer of the project. (early on I bumped the required Clojure from 1.2 to 1.7)
As usual the release features also small bug-fixes and internal improvements. One such improvement was the introduction of
matcher-combinatorsin our test suite. (which was the main motivation to bid farewell to Clojure 1.7) You can check out the release note for a complete list of changes.That’s all I have for you today. I hope we’ll have more exciting nREPL news to share by nREPL’s “official” birthday, October 8th.1 Big thanks to everyone who has contributed to this release and to all the people supporting my Clojure OSS work! In the REPL we trust! Keep hacking!
-
nREPL 0.1 was released on Oct 11, 2015. ↩
-
-
Weird Ruby: Anonymous Heredocs
Heredocs in Ruby are quite common, quite flexible, and… somewhat weird. Still, this doesn’t stop people from suggesting more features for them, like this (rejected) proposal for an anonymous heredocs syntax:
# regular Ruby code Markdown.render <<~MARKDOWN # Hello there This is a Markdown file. See? 1. This is a list 2. With items 3. And more items MARKDOWN # proposed syntax Markdown.render <<~ # Hello there This is a Markdown file. See? 1. This is a list 2. With items 3. And more items ~>>Even though this proposal didn’t make it, you can get pretty close by just using
_as your heredoc delimiter:Markdown.render <<~_ # Hello there This is a Markdown file. See? 1. This is a list 2. With items 3. And more items _Looks a bit weird, but it gets the job done.
That’s all I have for you today. Keep Ruby weird!
-
CIDER 1.18 ("Athens")
Great news, everyone - CIDER 1.18 (“Athens”) is out!
This is a huge release that has an equal amount of new features, improvements to the existing ones, and also trimming down some capabilities in the name of improved efficiency and maintainability.
I’m too lazy to write a long release announcement today, so I’ll just highlight the most important aspects of CIDER 1.18 and how they fit our broader vision for the future of CIDER.
Let’s go!
Reduced surface area
- CIDER 1.18 dropped support for Boot and Emacs 26. Boot development has been frozen for many years, and it’s now a long past due to migrate to other build tools.
- CIDER no longer bundles Puget dependency. Puget is still supported as a pretty-printer for all CIDER output, but you need to add it to dependencies explicitly.
- Haystack is no longer included. With it, we removed some largely unknown facilities for parsing printed stacktraces and presenting them inside
*cider-error*buffer. - Replaced the outdated
thunknyc/profiledependency with a homegrown implementation in Orchard.
I’m happy that we continue on the path of reducing the 3rd-party dependencies in
cider-nrepland rely more and more on functionality optimized for our use-cases, living in Orchard. Looking back, at some of the decisions I’ve taken in the past - I sometimes regret going overboard with the feature set (we have so many features today, that even I occasionally forget about some of them) and the dependencies needed to provide certain features. Going forward I hope to gradually reduce the feature set and the dependencies by:- removing features that are rarely used
- making certain dependencies optional (instead of bundling everything with
cider-nrepl)
Inspector
Our beloved inspector got a lot better!
- New analytics module (orchard#329) (shows you some useful info about the data you’re inspecting)
- Table view mode (orchard#331) (I think you’ll totally love this!)
- Pretty-printing mode (#3813) and a command to separately pretty-print the currently inspected value (#3810)
That’s how the analytics and the table view look:
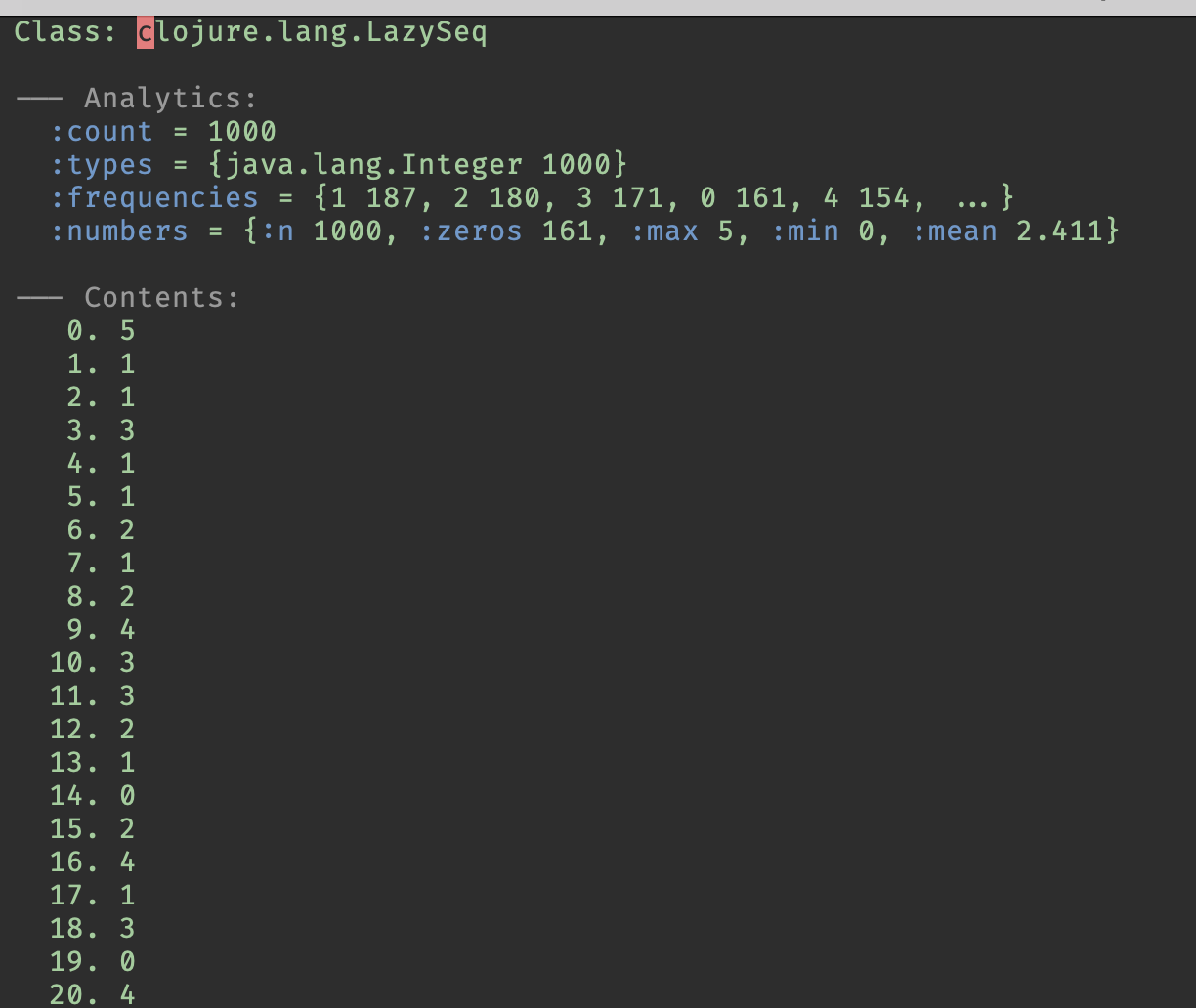
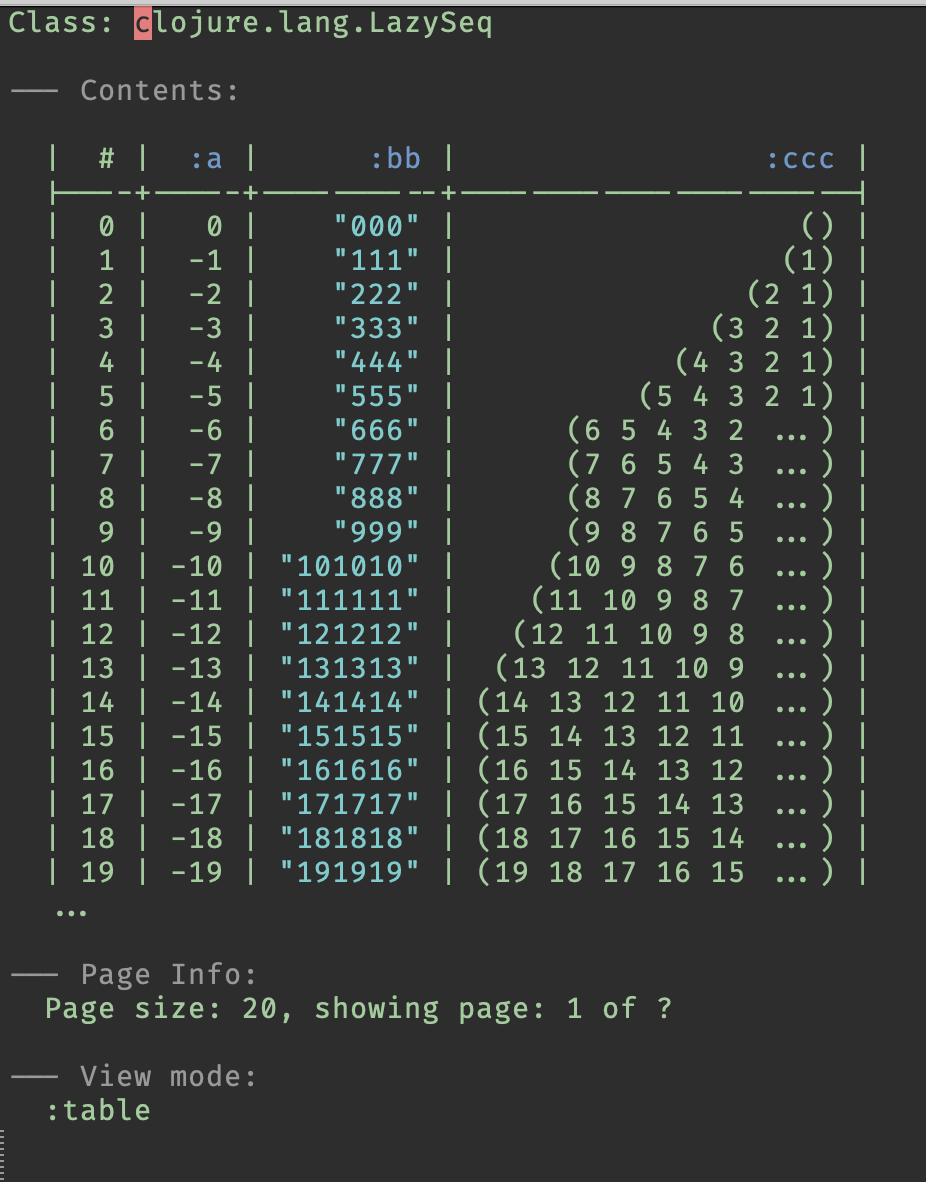
Cool stuff!
Error handling
- In exchange for removing Haystack, CIDER now allows jumping to munged Clojure functions and Java methods anywhere from the source buffers or the REPL. This means that you can press
M-.on printed frames likeclojure.core$with_bindings_STAR_.doInvokeorclojure.lang.Compiler$InvokeExpr.evalwithin the exception, and CIDER will take you there. - Stacktrace processing has been greatly simplified and optimized. You may notice that the delay between an exception occuring and
*cider-error*buffer popping up disappeared, especially in big projects. - Ex-data is now always displayed for each exception cause which has it, albeit in an abbreviated form. You can click or press
RET(a.k.a.Enter) on to open it in the inspector (#3807).
I’m guessing some of those changes might be considered slightly controversial (especially the last item), but I think they are a bit step towards simplicity and more internal consistency.
Misc features
- Completions got better with priority-based sorting and fuzzy-matching enabled by default (so you can complete unimported short classnames, and things like
cji,rkv, etc.) - The middleware that powers dynamic font-locking was made trememdously faster and more memory efficient on both Clojure and Emacs sides of CIDER. Again, this effect would be more pronounced in large codebases.
This optimization is well overdue, and perhaps it will encourage more editors to embrace the
track-statemiddleware, as I think it’s one of the coolest aspects of CIDER. - Added support for dynamic indentation in clojure-ts-mode (#3803)
Side note - I’ve been spending a lot of time on
clojure-ts-modelately and it’s shaping up pretty nicely. If you’re happy withclojure-modethere’s no real reason to switch yet, but if you’ve experienced performance issues with font-locking on indentation you may want to check outclojure-ts-mode.I’m happy to report that I’ve also finally started to clean up the numerous compilation warnings introduced in Emacs 29. Most of the meaningful problems are now addressed and the bulk of the remaining work is related to a new rule for quoting
'in docstrings, which is annoying but not particularly important.Epilogue
This release is named “Athens” for a reason - Athens is one of the greatest cities in the world1 and I think that’s one of the greatest CIDER releases!
For me that’s one of the most important CIDER releases in the past couple of years, if not the most important. We’ve tackled a lot of long-standing problems and we’ve started to simplify the internals of CIDER. The feedback we got from the “State of CIDER” survey really helped us with some of the decisions - stay tuned for a detailed analysis of all the feedback we’ve collected there.
As usual - a huge shoutout to all the contributors and “Clojurists Together” for their support! A special thanks to Sashko Yakushev, who has been firing on all cylinders lately, and was once again the driving force behind most of the work in this release. You’re a legend, buddy!
Sadly, the amount of financial support CIDER is receiving has dropped a lot in the past 3 years (by about 50%). I hope the situation will change, as solid and predictable financial backing is the only way to ensure the long-term future of CIDER and friends.
This is all I have for you today. I hope you’ll have as much fun using it, as we had developing it! Keep hacking!
-
And one of my favorite cities. I’ve got a lot of fond memories of working on CIDER there. ↩
-
Projectile Introduces Significant Caching Improvements
One of Projectile’s key features has always been the ability to cache the files in a project, so next time need to do something with them you’d skip the potentially expensive project file indexing step. The feature has always worked reasonably well, but it suffered from a couple of design flaws that I’ve been meaning to address for a while:
- The cache for all projects is stored in the same file, which means that often you need to load information that you don’t really need. Also - storing all the cache data in the same file means that there’s a higher chance that the cache would get corrupted for one reason or another.
- When caching is enabled, Projectile loads the data from the cache file when
projectile-modeis enabled. That causes two problems:- The mode’s init is slower than it could be
- The cache is not loaded unless you enable
projectile-mode
I’m happy to report that I finally got to doing something about the problems listed above!1 In a nutshell:
- Now each project gets its own cache file in the root of the project’s
directory. (named
.projectile-cache.eldby default)2 I’ve opted for this approach over something like.emacs.d/cache, as it avoids the need to hash the project paths. (so cache files could be mapped to project root paths) I might change this behavior in the future, depending on the user feedback I receive. - The cache is read from disk only when you trigger
projectile-find-filefor the first time. - Both reading and writing the cache file is much faster, as you’re only reading/writing the cache file for the currently visited project.
This means that Projectile’s loading time is much snappier if you’re a heavy cache user.
I’ve also addressed a common problem for people using Projectile over TRAMP - that writing to the cache file can be quite slow there if you’re working on huge project. The writing of the cache when individual files are added to it is now deferred using
run-with-idle-timer3, which means that you’ll never experience a lock-up right after creating a new file within a project. Perhaps even more importantly - I’ve introduced the concept of “transient” cache. Basically it lives only in memory and is not persisted to a file.4 Going forward this is going to be the default caching behavior in Projectile, as I think it offers a better blend of performance and convenience. To enable the traditional “persistent” cache you’ll have to add this to your config:(setq projectile-enable-caching 'persistent)To make things better I’ve also reorganized how known projects are initialized, so now no IO operations happen during Projectile’s initialization and it’s lightning fast! To illustrate this with a bit of code:
;; projectile-mode init before ;; ;; initialize the projects cache if needed (unless projectile-projects-cache (setq projectile-projects-cache (or (projectile-unserialize projectile-cache-file) (make-hash-table :test 'equal)))) (unless projectile-projects-cache-time (setq projectile-projects-cache-time (make-hash-table :test 'equal))) ;; load the known projects (projectile-load-known-projects) ;; update the list of known projects (projectile--cleanup-known-projects) (when projectile-auto-discover (projectile-discover-projects-in-search-path)) ;; projectile-mode init now ;; ;; nothing IO-related to show hereLast week I’ve started to prepare for the release of Projectile 2.9, which will bring a lot of bug fixes and improvements. I know that a lot of people have probably written off Projectile by now, but I still believe that it has a place in the broader Emacs ecosystem (as a community-driven and more feature-rich alternative of
project.el) and the best is yet to come!That’s all I have for you today. Keep hacking!
P.S. I’d appreciate it if more Projectile users experimented with the current snapshot package, before Projectile 2.9 gets officially released.
-
See https://github.com/bbatsov/projectile/commit/5061bd8dcd9f4d0e874884272f88b10892d15da3. ↩
-
You’ll probably want to add this file to your
.gitignore. Or not, as the paths stored in it are relative to the project’s root, so they can actually be reused across different machines. ↩ -
See https://github.com/bbatsov/projectile/commit/0efac68c82d8ebdb3fd83ea5e530c4b816c87f8f. ↩
-
See https://github.com/bbatsov/projectile/commit/a4a6cacd908bc614d60c6233a7f224baebfe1178. ↩
-
A Simpler Way to Deal with Java Sources in CIDER
For ages dealing with Java sources in CIDER has been quite painful.1 Admittedly, much of the problems were related to an early design decision I made to look for the Java sources only in the classpath, as I assumed that would be easiest way to implement this. Boy, was I wrong! Countless of iterations and refinements to the original solution later, working with Java sources is still not easy. enrich-classpath made things better, but it required changes to the way CIDER (nREPL) was being started and slowed down the first CIDER run in each project quite a bit, as it fetches all missing sources at startup. It’s also a bit trickier to use it with
cider-connect, as you need to start nREPL together withenrich-classpath. Fortunately, my good friend and legendary Clojure hacker Oleksandr Yakushev recently proposed a different way of doing things and today I’m happy to announce that this new approach is a reality!There’s an exciting new feature waiting for you in the latest CIDER MELPA build. After updating, try turning on the new variable
cider-download-java-sources(M-x customize-variable cider-download-java-sourcesand then toggle to enable it). Now CIDER will download the Java sources of third-party libraries for Java classes when:- you request documentation for a class or a method (
C-c C-d C-d) - you jump to some definition (
M-.) within a Java class
Note that
eldocwon’t trigger the auto-download of Java sources, as we felt this might be harmful to the user experience.This feature works without
enrich-classpath.2 The auto-downloading works for both tools.deps and Leiningen-based projects. In both cases, it starts a subprocess of eitherclojureorleinbinary (this is the same approach that Clojure’s 1.12add-libutilizes).And that’s it! The new approach is so seamless that it feels a bit like magic.
This approach should work well for most cases, but it’s not perfect. You might have problems downloading the sources of dependencies that are not public (i.e. they live in a private repo), and the credentials are non-global but under some specific alias/profile that you start REPL with. If this happens to you, please report it; but we suspect such cases would be rare. The download usually takes up to a few seconds, and then the downloaded artifact will be reused by all projects. If a download failed (most often, because the library didn’t publish the
-sources.jarartifact to Maven), CIDER will not attempt to download it again until the REPL restarts. Try it out in any project by jumping toclojure.lang.RT/toArrayor bringing up the docs forclojure.lang.PersistentArrayMap.Our plan right now is to have this new feature be disabled by default in CIDER 1.17 (the next stable release), so we can gather some user feedback before enabling it by default in CIDER 1.18. We’d really appreciate your help in testing and polishing the new functionality and we’re looking forward to hear if it’s working well for you!
We also hope that other Clojure editors that use
cider-nreplinternally (think Calva,iced-vim, etc) will enable the new functionality soon as well.That’s all I have for you today! Keep hacking!
P.S. The State of CIDER 2024 survey is still open and it’d be great if you took a moment to fill it in!
- you request documentation for a class or a method (
Subscribe via RSS | View Older Posts